[TOC]
Abstract
主流的序列翻译模型一般是基于复杂的循环或卷积神经网络,他们包括encoder和decoder。最好的模型效果是通过Attention机制将encoder和decoder连接的。我们提出了一个简单的网络结构:Transformer,完全基于Attention机制,而不是整体的循环或卷积网络。在两个翻译任务中表明,模型效果更好,更容易并行化和训练。
1. Introduction
在实践中,循环神经网络LSTM和GRU稳居序列模型和翻译(如语言模型,机器翻译)第一。许多研究者推进了循环语言模型和encoder-decoder结构工作。RNN通常考虑沿输入和输出序列的符号位置的计算。将位置与time step对齐(Aligning),从而生成隐层状态序列$h_t$, t表示位置,$h_{t-1}$是前一个状态。最近的工作已经通过因子化和条件计算实现了计算效率的显着改善,同时在后者的情况下也提高了模型性能。然而,顺序计算的基本约束仍然存在。
Attention机制已成为序列建模和翻译模型等任务中的重要部分,它能忽略输入和输出中的距离从而对依赖建模。绝大多数情况下,Attention机制都是和RNN相连的。
本文提出了Transformer模型架构,其完全依赖于Attention机制来描述输出与输出间的全局依赖。Transformer更易实现并行化,在8个P100GPU上训练12个小时就可以达到最好效果。
3. Model Architecture
大部分高效的神经序列翻译模型都是encoder-decoder结构。encoder将输入的符号序列$(x_1,…,x_n)$表示成连续表示序列$\mathbf{z}=\left(z_{1}, \dots, z_{n}\right)$. 在给定$\mathbf{z}$后,decoder生成输出序列$\left(y_{1}, \dots, y_{m}\right)$,每次生成一个。每一step,模型是自回归(auto-regressive), 将上一个输出作为当前额外的输入。
Transformer模型使用stacked self-attention和point-wise来遵循这样整体架构,全连接层连接encoder和decoder。如下图所示:
3.1 Encoder and Decoder Stacks
Encoder:encoder是由一个$N=6$的栈层。每一层包含两个子层。第一个是multi-head self-attention机制,第二个是一个简单的position-wise全连接的前向神经网络。我们使用残差来连接每个两个子层,并使用layer normalization。换句话说,每个子层的输出为$\text{LayerNorm}(x+\text{Sublayer}(x))$,$\text{Sublayer}(x)$是由其子层自己实现的。为了方便残差的连接,模型中的子层以及嵌入层,其输出维度都是$d_{\text{model}}=512$。
Decoder: decoder同样是由一个$N=6$的栈层构成的。此外,encoder中每层的两个子层,添加了第三个子层:在encoder stack输出上的multi-head attention。与encoder一样,我们使用残差连接每个子层,并使用Layer Normalization。我们还修改了了decoder stack中self-attention子层来保存从attending到后面位置的位置信息。masking结合了嵌入偏移一个位置的情况,保证了对于位置$i$的预测仅依赖于小于$i$的位置的已知输出。
3.2 Attention
Attention功能可以看成是将query和一系列key-value对映射成输出,query,keys,values和output都是向量。oputput是values的加权和,对每个value设置的权重是通过计算query和其对应的key的相关函数(compatibility function)得到的。
3.2.1 Scaled Dot-Product Attention
我们使用的attention记为”Scaled Dot-Product Attention“,如图所示。输入是由queries、$d_k$维度的keys、$d_v$维度的values组成。首先使用query与所有的keys进行点积(dot products)运算,并除以每一个$\sqrt{d_k}$,然后使用softmax函数来得到values上的权重。
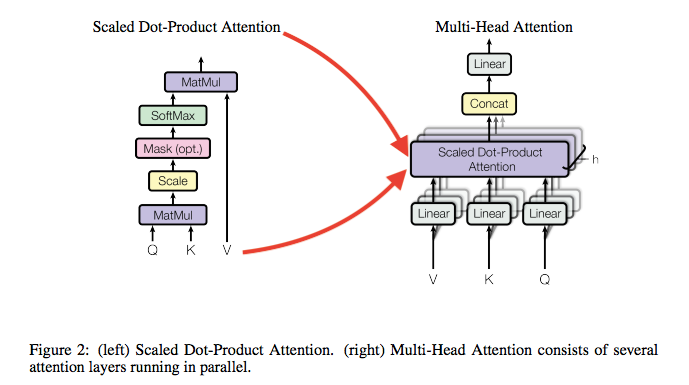
在实现中,我们同时在一组queries上计算attention函数,并记为矩阵$Q$。kyes和values也组成矩阵$K$和$V$。我们计算的输出矩阵为:
$$(Q, K, V)=\operatorname{softmax}\left(\frac{Q K^{T}}{\sqrt{d_{k}}}\right) V \tag{1}$$
两种最常用的attention函数是 additive attention 和 dot-product(multiplicative) attention。除了除数$\sqrt{d_k}$外,点积attention与我们的算法是一样的。加法attention是使用单隐层前向网络来计算相关函数。两种方式在理论上复杂度是相似的,由于dot-product可以使用高度优化的矩阵代码实现,所以它在应用中更快,空间使用也更加有效。
尽管当$d_k$值比较小的时候,两种机制性能相似,但$d_k$变大时候,加法attention不需要缩放,比dot product attention表现更好。我们认为,当$d_k$很大的时候,点积大幅增大,将softmax函数推向具有极小梯度的区域。为了避免这个影响,我们使用$\sqrt{d_k}$来缩放点积。
3.2.2 Multi-Head Attention
相比于使用单一attention的$d_{model}$维的keys,values和queries,我们发现,经过$h$次学习的线性映射将query,keys,values分别映成$d_k,d_k,d_v$是有效的。
Multi-head attention允许模型抽取不同表示子层空间的任意位置的信息。相比于单个attentin head,平均值抑制了这一点。
$$\begin{aligned} \text { MultiHead }(Q, K, V) &=\text { Concat }\left(\text { head }{1}, \ldots, \text { head }{\mathrm{h}}\right) W^{O} \ \text { where head }{\mathrm{i}} &=\operatorname{Attention}\left(Q W{i}^{Q}, K W_{i}^{K}, V W_{i}^{V}\right) \end{aligned}$$
此处,映射是参数矩阵$W_{i}^{Q} \in \mathbb{R}^{d_{\text { model }} \times d_{k}}$,$W_{i}^{K} \in \mathbb{R}^{d_{\text { model }} \times d_{k}}$,$W_{i}^{V} \in \mathbb{R}^{d_{\mathrm{model}} \times d_{v}}$,和$W^{O} \in \mathbb{R}^{h d_{v} \times d_{\mathrm{mode}}}$。
在本文中,我们设置$h=8$来表示attention的 层或头。对每个attention我们使用$d_{k}=d_{v}=d_{\text { model }} / h=64$。由于对每个attention降维,整体计算的损失与全维度的单头(single-head)attention是接近的。
3.2.3 Applications of Attention in our Model
Transformer使用multi-head attention有三种方式:
在”encoder-decoder attention”层,queries来自于之前的decoder层,然后记忆的keys和values来自于encoder的输出。这允许decoder中的每个位置再能在输入序列的所有位置上进行attention。这于seq2seq中的attention机制相似。
encoder包含self-attention层。在每个self-attention层,所有的keys,values,queries都来自前一encoder层的输出。encoder中的每个位置都能对encdoer所有的历史输出进行attention
同样,self-attention层应用于decoder,这允许decoder的每个位置能对decoder的位置(包括当前位置)进行attention。我们需要防止decoder中的左向信息流来保持自回归属性(auto-regressive property)。我们通过masking(设置为$-\infty$)softmax输入中与非法连接相对应的所有值来实现对点积attention的内部缩放。
3.3 Position-wise Feed-Forward Networks
在attention的子层,encoder和decoder中的每一层都是由一个全连接的前向神经网络组成。它是由两个线性变换和ReLU激活函数组成的:
$$\mathrm{FFN}(x)=\max \left(0, x W_{1}+b_{1}\right) W_{2}+b_{2} \tag{2}$$
线性变换在所有不同的位置上是一样的,不同层间的参数是不一样的。另一种理解是看成两个kernel size为1的卷积核。输入和输出维度是$d_{\text { model }}=512$,内层网络维度为$d_{f f}=2048$。
3.4 Embedding and Softmax
与其它序列转换模型类似,我们使用embedding来将输入tokens和输出tokens转换成$d_{model}$维向量。我们同样使用学习的新型变化和softmax函数来将decoder输出转换成预测的下一个token概率。在我们的模型,我们在两个embedding layers 和pre-softmax 线性转换中共享同样的权重参数,这与 Using the output embedding to improve language models相似。在embedding层,我们将权重与$\sqrt{d_{\text { model }}}$相乘。
3.5 Positional Encoding
由于我们的模型没有循环和卷积层,为了使模型能更好的利用序列的排列信息,我们必须加入输入序列的相对或绝对的位置信息。处于此点考虑,我们在encoder stacks和decoder stacks底部添加了”positional encodings”到输入embedding。positional encodings与embedding维度一样,都是$d_{model}$,因此二者可以相加。还有很多其它位置信息的编码方式 Convolutional sequence to sequence learning。
在本文中,我们使用sine和cosine函数来计算频率:
$$
P E_{(p o s, 2 i)}=\sin \left(p o s / 10000^{2 i / d_{\mathrm{model}}}\right) \
P E_{(p o s, 2 i+1)}=\cos \left(p o s / 10000^{2 i / d_{\mathrm{model}}}\right)
$$
其中$pos$是位置,$i$是维度。这是说,positional encoding的每个维度都对影成了sin值。波长形成几何级数($2\pi-10000\cdot2\pi$).我们选择这个函数是假设它允许模型能容易学习到相对位置,因为对任意固定的偏移项$k$,$PE_{pos+k}$能由$PE_{pos}$的线性函数表示。
我们还实验了其它positional embedding,结果相似。
4. Why Self-Attention
在这个章节,我们对比了self-attention与循环和卷积层各个方面。循环和卷积通常用来将符号序列$\left(x_{1}, \dots, x_{n}\right)$表示成另一个等长序列$\left(z_{1}, \dots, z_{n}\right)$,$x_{i}, z_{i} \in \mathbb{R}^{d}$。就像电影的序列模型encoder或decoder中的隐层。我们采用了三个必要条件。
- 每层的整体计算复杂度,
- 能否并行化,通过所需的最小操作数来衡量
- 网络中远距离依赖的路径长度
| Layer Type | Complexity per Layer | Sequential Operations | Maximum Path Length |
|---|---|---|---|
| Self-Attention | $O(n^2\cdot d)$ | $O(1)$ | $O(1)$ |
| Recurrent | $(n\cdot d^2)$ | $O(n)$ | $O(n)$ |
| Convolutional | $O(k\cdot n \cdot d^2)$ | $O(1)$ | $O(log_k(n))$ |
| Self-Attentoin(restricted) | $O(r\cdot n\cdot d)$ | $O(1)$ | $O(n/r)$ |
如上表所示,一个self-attention层以恒定数量的顺序执行操作来连接所有的位置,而循环层需要$O(n)$序列操作。在计算复杂度上,当序列长度$n$比表示维度$d$小的时候,self-attention层比循环层要快。为了提高在长序列任务中的计算效果,self-attention能后限制成只考虑相应输出位置为中心的输入序列中size为$r$的位置。这能最大化path 长度为$O(n/r)$。我们计划以后进一步研究这个方法。
一层核维度为$k<n$的卷积层没有连接所有的输入和输出位置对。这样做需要在连续内核佛如情况下堆叠O(n/k)$卷积层,或者在扩展卷积的情况下需要$$o(log_k(n))$,增加网络中任何两个位置之间的最长路径的长度。在因子$k$下,卷积层通常比循环层代价更高。系数卷积能将复杂度降低至$O(k \cdot n \cdot d + n \cdot d^2)$,当$k = n$时,稀疏卷积的复杂度与self-attention层核point-wise层相结合(我们模型采用的方法)相同。
另一方面,self-attention能够生成可解性更强的模型。我们对比了我们模型中的attention分布核当前讨论的例子,放在附录中。不仅每个attention head能独立学习不同的任务,许多还表现出与句法核语义结构相关的行为。
备注分析
Complexity per Layer: 每层计算复杂度
Sequential Operations: 论文使用最小的序列来衡量并行化计算。对于传统的RNN,$x_1,x_2,…,x_n$序列需要逐步计算,而self-attention可以使用矩阵操作实现一步到位。
Path length between long-range dependencies: Path length的含义表示计算一个序列长度为n的信息所经过的路径长度。RNN需要从1-n逐次计算,CNN需要增加卷积层来扩大感受野,而self-attention只需要一步矩阵计算。所以self-attention可以比RNN更好解决Long Term Dependency问题。当然,如果序列长度n>序列维度d,可以使用限制(restricted)Attention。
此外,论文附录中表明Attention有更好的可解释性,能学习到一些语法和语义信息。
5 Traning
本届来介绍训练细节
5.1 Traning Data and Batching
我们使用斯坦福WMT2014English-German数据,包含4.5m语句。词汇表大约37000token。English-French使用著名的WMT2014English-French数据,包含36M语句核32000词汇。句子按照近似的长度来进行批处理。每个batch训练数据包含25000个源token和25000目标token组成的句子。
5.2 Hardward and Schedule
8个NVIDIA P100 GPUs.每步需要0.4秒。我们训练100000步或12个小时。对于较大版本的模型,每步需要1秒,训练300000步(3.5天)
5.3 Optimizer
使用Adam优化,$\beta_1 = 0.9, \beta_2 = 0.98, \epsilon = 10^{-9}$, 学习率:
$$
\text{lrate} = d_{\text { model }}^{-0.5} \cdot \min \left(\operatorname{step}{-} n u m^{-0.5}, \text { step }{-} n u m \cdot \text { warmup_oteps }^{-1.5}\right)
$$
这对应于对于第一个warmup_steps训练步骤线性地增加学习速率,并且此后与步数的反平方根成比例地减小它。 我们使用了warmup_steps = 4000。
5.4 Regularization
我们使用三种正则化手段:
- Residual Dropout 在每个子层的输出添加到子层的输入和归一化前,使用dropout。此外我们使用dropout来对encoder及decoder中的embedding和positional encoding求和。基本模型,$P_{d r o p}=0.1$。
- Label Smoothing 训练过程中我们使用类别平滑,$\epsilon_{l s}=0.1$。这降低了困惑度,模型学习更不确定,单BLEU得分增加了
- ?
6 Result
6.1 Machine Translation
6.2 Model Variations
7 Conclusion
在本文中,我们提出了Transformer,第一个完全基于attention的序列转换模型,用multi-head self-attention来替代encoder-decoder结构中常用的卷积层。
对于翻译任务,Transformer训练明显快于基于卷积核循环层的结构。在WMT2014英-德 英-法翻译任务上,达到了state of the art。在前一项任务中,打败了所有以前报道的。
balalal~
代码: https://github.com/ tensorflow/tensor2tensor
8 个人笔记
Attention is all you need这篇论文对Transformer模型的一些细节讲的并不是很清楚,multi-head attention是Transformer模型的核心,讲解的也不是非常多,以及训练的细节描述也不够:比如decoder中的中间子层如何理解?encoder与decoder中的KV有何不同?模型的loss是什么等等。在查阅一部分博客之后,稍微有了一些了解然后先记录下来。
8.1 Attention
基本Attention
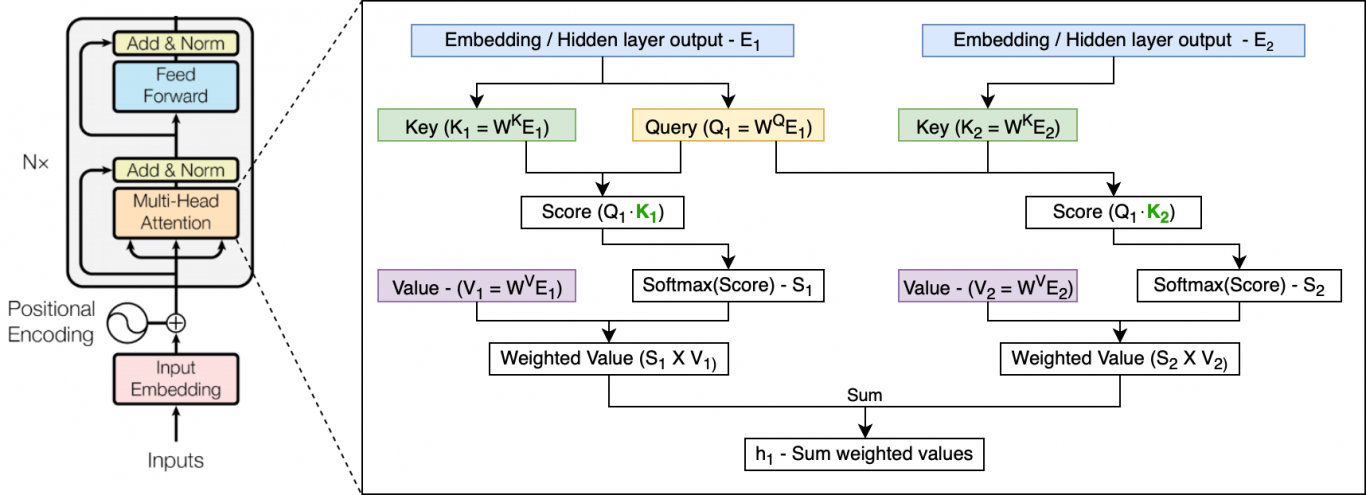
首先来解释下以前的attention,一般是指seq2seq中的attention机制,当然以前的attention也有很多类型,但区别不是非常大。Attention的思想简单的说,是在decoder的每个time-step时候,添加一个context向量,这个向量是在每一个encoder隐层状态上使用不同的权重计算得到。不同的time-step下,对encoder隐层状态上的权重(注意力)不同,从而帮助更好模型进行预测。那么这个权重是如何计算的呢?我们可以记为score函数,其输入为最后的encoder隐层状态$h_t$和当前decoder状态$\overline{h}t$(有的用的前一个隐层状态),score的实现有多种方式:
$$
\operatorname{score}\left(h{t}, \overline{h}{s}\right)=\left{\begin{array}{ll}{h{t}^{T} \overline{h}{s}} & {\text { Dot }} \ {h{t}^{T} W_{a} \overline{h}{s}} & {\text { General }} \ {v{a}^{T} \tanh \left(W_{a} \cdot \operatorname{concat}\left(h_{t}, \overline{h}_{s}\right)\right)} & {\text { Concat }}\end{array}\right.
$$
可以记为加法,乘法和MLP三种类型的attention。当然权重应该和为1,所以再使用softmax归一化一下。此外,如果是对所有的encoder的隐层状态进行权重计算,便是global attention,如果是对一部分位置进行attention则成为local attention。所以attention的实现是多样化的,但这些attention都是single-head,既不是multi-head也不是self-attention。详细的传统的Attention可以参考Attention模型详解)。
Transformer 中的Attention
Transformer中的attention初步上手看到QKV会非常的懵,其实整理一下并不难。将QKV代入到以往的Attention中对应概念就很好理解了。在基本Attention中,随着decoder端的time-step,我们将decoder的隐层状态$\overline{h}_t$与encoder隐层状态$h_t$进行权重(attention)的计算,每个encoder的隐层状态都会得到一个权重值,二者的这种对应关系与k,v是一样的,所以K,V的理解就比较简单了。在基础Attention中,Q表示decoder端隐层状态,K=V都表示encoder的隐层状态。
我们来看Transformer中的Attention:
首先QK的计算是使用MatMul,即使用的是乘法Attention(论文中称为Scaled Dot-product Attention),然后经过了缩放,以及Mask(可选),再经过Softmax得到归一化的权重,然后与V相乘得到最后的输出。
$$
(Q, K, V)=\operatorname{softmax}\left(\frac{Q K^{T}}{\sqrt{d_{k}}}\right) V
$$
在公式中,QK的维度为$d_k$,V的维度为$d_v$。$\sqrt{d_k}$是为了对数值进行缩放,否则softmax计算后的效果不够’soft’。公式比较好理解,但QKV在模型中对应还没有说到,往下看。
8.2 Multi-Head Attention
顾名思义,multi-head attention是将Attention添加了一个维度,使用多个attention机制去计算。但是根据上一节中如果,QKV不变的话,得到的结果也是一样的,该如果实现multi呢?Transformer是添加了一层对QKV的线性映射。论文中使用了$h=8$个head(attention layer),所以添加了三个学习权重:$W_{i}^{Q} \in \mathbb{R}^{d_{\text { model }} \times d_{k}}$,$W_{i}^{K} \in \mathbb{R}^{d_{\text { model }} \times d_{k}}$,$W_{i}^{V} \in \mathbb{R}^{d_{\mathrm{model}} \times d_{v}}$,和$W^{O} \in \mathbb{R}^{h d_{v} \times d_{\mathrm{mode}}}$,其中$i \in [0, h-1]$。最后将所有single head attention的结果拼接在一起,乘以一个权重后作为最后的输出。
$$
\begin{aligned} \text { MultiHead }(Q, K, V) &=\text { Concat }\left(\text { head }{1}, \ldots, \text { head }{\mathrm{h}}\right) W^{O} \ \text { where head }{\mathrm{i}} &=\text { Attention }\left(Q W{i}^{Q}, K W_{i}^{K}, V W_{i}^{V}\right) \end{aligned}
$$
如果使用代码去实现这里,很直接的思想是使用for head in heads:,但更好的实现方式是使用矩阵,详细的图示可以参考The Illustrated Transformer[译]。multi-head attention是作为Transformer一个子层模块的,论文中提到为了方便,模型的嵌入维度及子层维度是一样的,$d_{model} = 512$,而QKV的维度设置为$d_{k}=d_{v}=d_{\mathrm{model}} / h=64$。这样最后拼接后的维度与512一致。
8.3 Self-Attention
在基础Attention中,Q来自decoder,KV一样来自encoder。而Self-Attention是指Q=K=V。:laughing:
8.4 Position Extraction
Transformer模型包含两类子层,Multi-Head Attention已经讲完,还有一个细节在于,在Multi-Head Attention添加了残差连接(Add)和Layer Norm,同样另一个子层Feed Forward也有相同处理。
Attention is all you need这篇论文将’抛弃RNN及CNN的,完全基于Attention机制的序列转换模型’作为最大的创新点说明。multi-head attention能使序列任意位置的信息进行抽取,这很明显丢失了序列的排列信息。因此,Transformer模型采用了两种方式来进行处理:
Positional Encoding
对词序位置信息的编码方式有很多,Google发现下面这种公式处理和其他方式效果一样,所以选择公式处理:
$$
P E_{(p o s, 2 i)}=\sin \left(p o s / 10000^{2 i / d_{\mathrm{model}}}\right) \P E_{(p o s, 2 i+1)}=\cos \left(p o s / 10000^{2 i / d_{\mathrm{model}}}\right)
$$
$pos$是位置,$i$是维度,也就是说每个维度都使用Positional Encoding编码成了一个的sin值,这样得到的维度与输入序列的嵌入维度一致,就可以将两个嵌入加在一起。由sin的性质可以发现,$PE_{pos+k}$可以由$PE_{POS}$表示,这表示记录了词序的相对位置信息。Position-wiseFeed-ForwardNetworks
虽然标题中带了Position,但和序列的直接关系好像并不强。这一个子层是使用ReLU和线性映射组成的:
$$
\mathrm{FFN}(x)=\max \left(0, x W_{1}+b_{1}\right) W_{2}+b_{2}
$$
子层的输入和输出维度都是$d_{model}=512$。$W_1$维度为2048。
8.4 The Final Linear and Softmax Layer
模型预测单词是使用线性映射和softmax两层来实现的。
8.5 Mask
Mask顾名思义就是掩码,是为了对某些位置进行遮罩,使其不产生效果。
Transformer模型涉及了两种mask:padding mask和sequence mask。
Padding Mask
在数据的输入中,每个序列的长度是一样的,因此要对序列进行对齐,对较短的序列进行填充。这些填充位置不应该被attention注意,所以需要进行mask。具体的做法是,将这些位置加上一个非常大的负数,这样经过softmax,其值接近于0。
Sequence Mask
sequence mask 是为了让decoder不能看见未来的信息。也就是对应序列,在time_step为t的时刻,decoder应该只依赖于t时刻前的输出。具体的做法是:产生一个上三角矩阵,上三角的值全为1,下三角的值权威0,对角线也是0。把这个矩阵作用在每一个序列上,就可以达到我们的目的啦。
所以:
- 在decoder中,两种mask都使用,具体实现是两种mask相加
- 其他情况都是padding mask
8.6 其它细节
论文中还提到了使用了Dropout、变化的学习率、Embedding层权重。
- 在encoder中,每层的输出一次传递到下一层,最后得到K,V是传输到decoder中的每个’encoder-decoder attention’中
- 在decoder中,是使用上一层的输出作为Q,而K和V是来自encoder的输出。
- decoder中使用了mask,将后续的位置设置为$-\infin$,避免后面的翻译结果对当前学习的影响。
算法整理:
$$
P\left(w^{1}, \ldots, w^{n}\right)=\prod_{j=1}^{n} p\left(w^{j} | w^{1}, \ldots, w^{j-1}\right)
$$
模型结构:
$$
h_{0}=U W_{\mathrm{embed}}+W_{\mathrm{position}} \
h_{l}=\text { transformer-block }\left(h_{l-1}\right) \forall l \in[1, n] \
P(u)=\operatorname{softmax}\left(h_{n} W_{\text { embed }}^{T}\right)
$$
$U$是输入序列的one-hot形式,维度为$d_n\times d_{vocab}$,$W_{embed}$是嵌入矩阵,维度$d_{vocab} \times d_{model}$。$n$表示stack size,论文中为6。
Transformer block:
transformer-block:
input: $h_{in}$
output: $h_{out}$
$h_{m i d}=\text { LayerNorm }\left(h_{i n}+\text { MultiHead }\left(h_{i n}\right)\right)$
$h_{o u t}=\text { LayerNorm }\left(h_{m i d}+\mathrm{FFN}\left(h_{m i d}\right)\right)$
$h_{in},h_{out} \in \mathbb{R}^{d_{n} \times d_{\mathrm{model}}} $,$d_n$是输入序列维度
MultiHead Attention:
$\text{MultiHead}(h)=\text { Concat }\left[\text {head}{1}, \ldots, h e a d{m}\right] W^{O}$
$\text{where} head_i = \text{Attention}(Q,K,V)$
$\text{where} Q,K,V = hW_i^Q,hW_i^K,hW_i^V$
$m$是head数量,输入$h$维度是$d_n \times d_{model}$,输出维度也是$d_n \times d_{model}$。
Self-Attention:
$\text{Attention}(Q,K,V) = \text{softmax} (\frac{QK^T}{\sqrt{D_k}})V$
其中Q,K维度为$d_n\times d_k$,V的维度为$d_n \times d_v$
Position-wise Feed Forward Neural Network:
$\operatorname{FFN}(h)=\operatorname{ReLU}\left(h W_{1}+b_{1}\right) W_{2}+b_{2}$
$W_1 \in \mathbb{R}^{d_{model}\times d_{ff}}, W_2 \in \mathbb{R}^{d_{ff}\times d_{model}}$,$h$的维度为$d_n \times d_{model}$。
收藏一张图: