A Fast and Accurate Dependency Parser using Neural Networks
Danqi Chen, Christopher D. Manning
Stanford University
Abstract
现在几乎所有的依赖解析器(dependency parsers)都是基于数百万个稀疏指示器特征(sparse indicator feature)进行分类。这些特征泛化能力差,计算成本高。本文提出了一种新的贪婪式(greedy),基于转移(trasition-based)依赖解析器(dependency parser)来实现神经网络学习。由于分类器学习和使用少量的dense feature,所以它运行快,不论是在中文还是英文上有LAS或UAS提高了2%。具体来说,我们的解析器能在92%的UAS数据上每秒处理1000个句子。
Introduction
现在,基于特征的判别式依赖解析器(feature-based discriminative dependency parser)(K¨ubler et al., 2009)。应用中基于转换的及其子类解析器都比较快速。
但这些解析器仍不完美。首先,从统计学角度来讲,他们使用数百万并不是很好的特征权重
,虽然整体上词汇特征和高级交互特征在提升算法,但没有足够数据来给这些权重正确赋值。其次,所有的解析器都需要手工设计特征模板,这需要专业性,通常并不完整。再而,许多特征模板在研究很少的问题:现在解析器,最大的耗时不是算法,而是特征提取。Bohnet说他的算法虽然有效,但99%的时候都在特征提取。
受词向量成功的启发(POS任务),我们想使用dense feature来解决问题。低维,密集的特征是不错的良好的开始。
然而,如何对配置信息中所有有用信息进行编码,如何建模基于密集表示的高层特征都是挑战。我们训练了一个神经网络分类器,来在trainsition-based 依赖解析器中做解析决策。神经网络能生成词向量,POS,和依赖标签。我们仅使用200个特征在中文和英文的两个不同雨来任务中取得快速而准确的效果。本文贡献:
- 展示解析任务中学习到密集特征(dense representation)的效果。
- 提出了新的神经网络结构,速度与精度兼有
- 介绍一种新的, 能更好得到高层交互特征的激活函数
2 Transition-based Dependency Parsing
基于转移的依赖解析旨在预测从初始配置到终端配置的转移序列,结果为依赖树。其效果如图所示: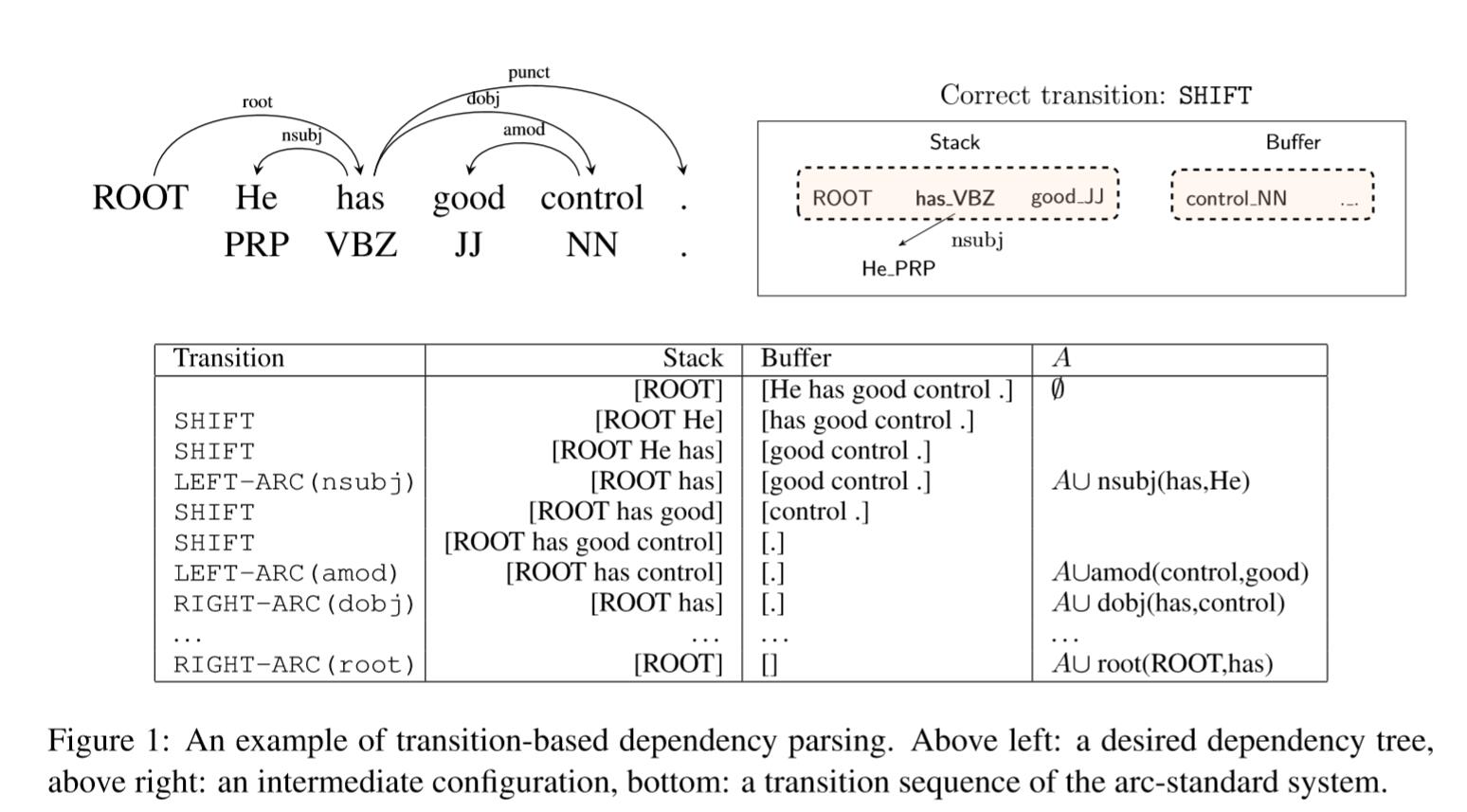
在本文中,我们使用贪婪解析,即使用分类器在从配置提取的他反正基础上对transition进行预测。这类解析器很要意思,他快速,虽有由于错误传播,准确率略低于基于搜索(search-based)的解析器.
本文采用arc-standard系统(Nivre 2004)。 configuration 的含义;$c = (s, b, A)$,分别是Stack, Buffer, Dependency Arc。初始化时候,$s = [ROOT], b = [w_1,w_2…w_n],A = \emptyset$。三个操作定义(可参考之前博文):
- LEFT-ARC(l):添加边$s1 \rightarrow s2$及label (l),并移除$s2$。约束 $|s>2|$
- RIGHT-ARC(l):添加边$s1 \leftarrow s2$,并将s1出栈。约束 $|s>2|$
- SHIFT将元素进栈。约束 $|b|>1$
Transitions共有 $|T|=2N_l+1$个。图一解释了Trasition序列例子,从初始配置到终端配置。
贪婪解析的本质目标是在给定configuration下,从$T$预测正确的transition。 从一个configuration可以得到以下信息:1. 所有单词及其词性POS标签 2. 每个单词的头及标签 3.单词在栈/缓冲区的位置,不管是否已出栈。
传统特征模板的弊端:
- 稀疏。特征稀疏,尤其是词汇化特征稀疏是NLP任务常见问题。我们对English Penn Treebank(表1)进行了特征分析。结果如表2.

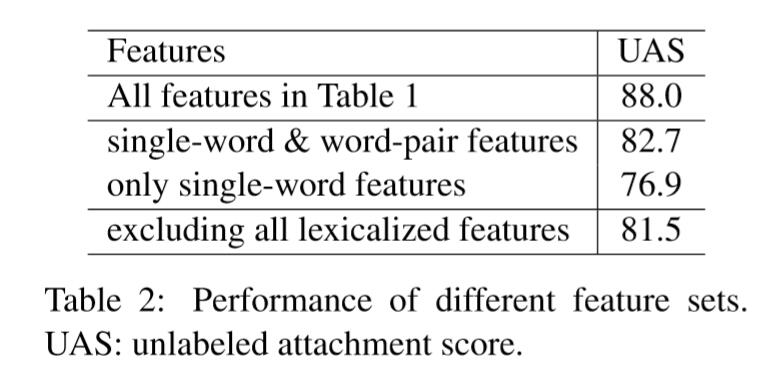 结果说明:1)词汇特征是必不可少的。2)单词对很重要,三词组也很重要。
结果说明:1)词汇特征是必不可少的。2)单词对很重要,三词组也很重要。 - 不完整。不完整性是现有特征模板的不可避免的问题。因为设计手工处理,无法包含每个有用单词对。
- 计算成本高。 indicator features的特征抽取代价很高。我们必须连接一些单词,POS标签,边标签来生成特征字符串,并在庞大的特征中来寻找。我们的实验中,95%的时间是特征计算。
到目前为止,我们已经讨论了基于转换的依赖解析的初步和稀疏指标特征的现有问题。 在接下来的部分中,我们将详细阐述我们的神经网络模型,以便通过实验评估来证明其效率。
3 Neural Network Based Parser
本节介绍神经网络模型和其细节,包括训练,加速解析。
3.1 Model
图2描述了网络结构,首先,词向量是一个$d$维向量,用$e_i^w \in \mathbb{R}^d$表示,整个嵌入矩阵用 $E^w \in \mathbb{R}^{d \times N_w}$ 表示, 其中 $N_w$ 为字典大小。同时我们还将POS标签和和边标签影射成$d$维度向量,$e_i^t,e_j^l$ 表示第$i$个POS标签,第$j$个标签。相应的,$E^t \in \mathbb{R}^{d\times N_t}$ 表示全部的POS标签,$N_t$ 为标签的数量。同理$E^l \in \mathbb{R}^{d\times N_l}$。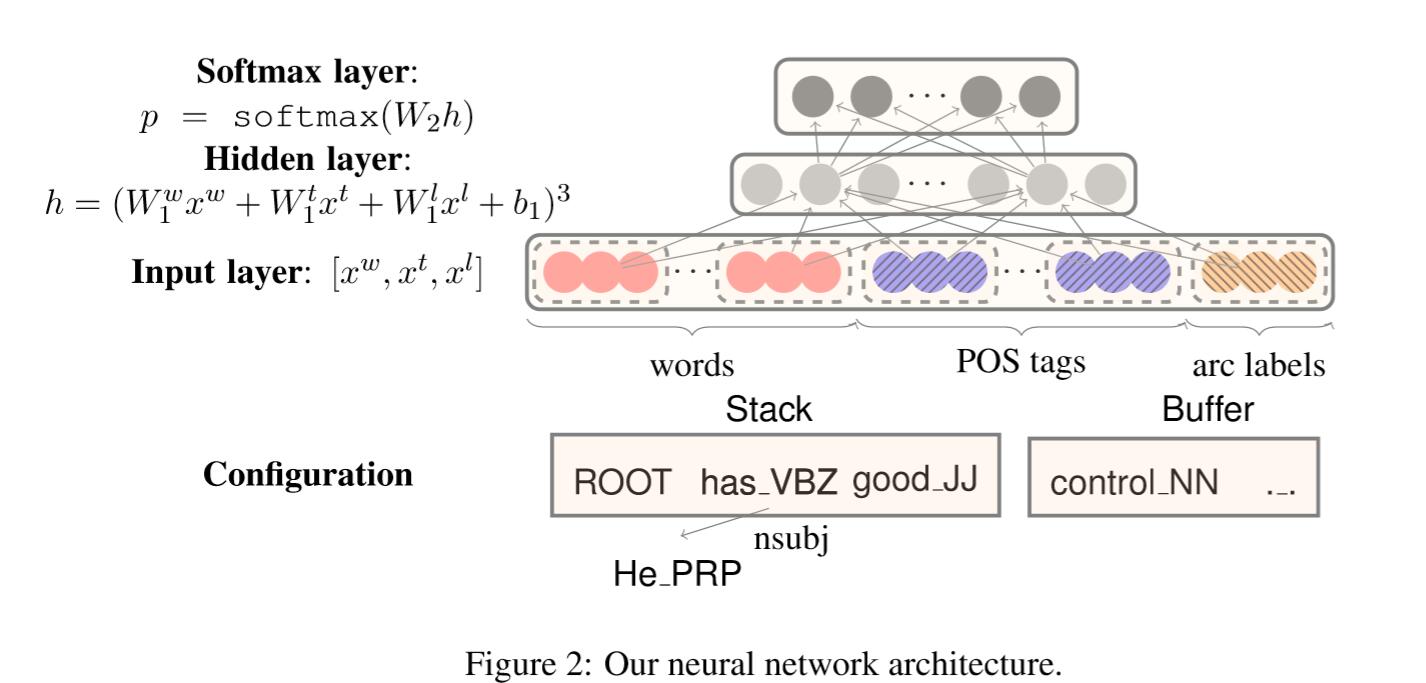
我们根据每种类型信息(字,POS或标签)的堆栈/缓冲区位置选择一组元素,这可能对我们的预测有效,分别用 $S^w, S^t, S^l$表示。如图2中,$S^t = {lc1(s2).t,s2.t,rc1(s2).t,s1.t}$ , 我们会依次抽取 $PRP, VBZ, NULL, JJ$。我们使用NULL来表示不存在元素。
我们建立了单隐层标准神经网络,我们从$S^w, S^t, S^l$插曲的元素将会输入到神经网络,用 $n_w, n_t, n_l$表示每种类型元素的数量。我们将 $x_w = [ e_{w1}^w; e_{w2}^w;…e_{wn_w}^w ]$添加到输入层, 其中 $S^w = {w_1,…,w_{n_w}}$。同样,我们添加$x^t$ , $x^l$到输入层。
隐层使用立方激活函数(cube activation function):
$$h = (W_1^wx^w + W_1^tx^t + w_1^lx^l + b1)^3$$
$W_1^w \in \mathbb{R}^{d_h \times (d \cdot n_w)}$ , $W_1^t \in \mathbb{R}^{d_h \times (d\cdot n_t)}$ , $W_1^w \in \mathbb{R}^{d_h \times (d \cdot n_l)}$ , $b1$是偏置项。
POS and label embeddings
据我们所知,这是首次尝试引入POS标签和圆弧标签嵌入而不是离散表示。尽管POS标签 $\mathbb{P} = {\text{NN, NNP, NNS, DT, JJ…}}$(英语)和边标签 $\mathbb{L} = {\text{amod,tmod,nsubj,…}}$(英语标准依赖)是相对比较小的离散集合,但它们像单词一样,仍然包含很多语义信息。比如NN(singularnoun)比DT(DETERMINER)和NNS(pluralnoun)更接近。我们想要有效抽取更加密集的表示。
Cube activation function
cube $g(x) = x^3$ 来替代sigmoid函数。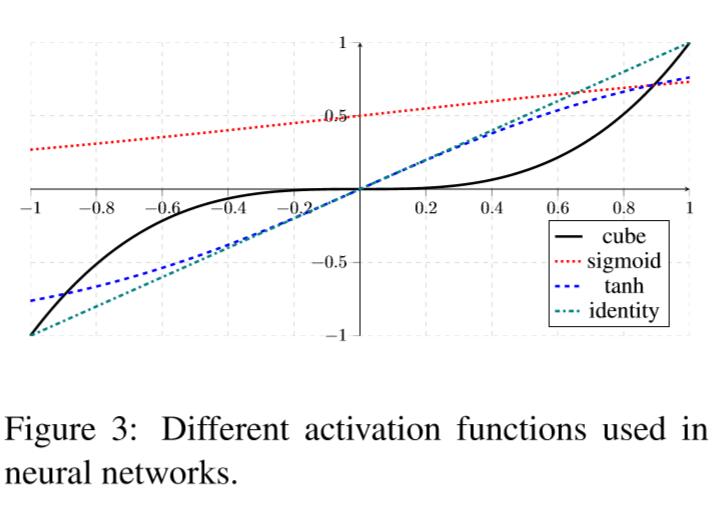
cube函数能对三个来自不同嵌入维度的$x_ix_jx_k$建模,能更好的适用于依赖解析。Cube函数仍需要理论分析。
The choice of $S^w, S^t, S^l$
根据(Zhang and Nivre, 2011)工作,我们选择rich set of elements。 细节上来说,$S^w$包含 $n_w$ = 18个元素:(1)stack及buffer的top 3元素:$s1,s2,s3,b1,b2,b3$;(2)stack top 2元素的第一和第二最可能的左/右孩子:$lc_1(s_i),rc_1(s_i),lc_2(s_i),rc_2(s_i), i=1,2$. (3)stack top 2元素的最可能的左/右元素的左/右元素。
POS标签数据与之对应(18)。边标签数据与之相应$S_l(n_l=12)$。我们的解析器胜在可以很简单的添加一组特征,省去手工繁琐步骤。
3.2 Training
我们首先根据训练语句创建样本 ${(c_i,t_i)}_{i=1}^m$,$c_i$是配置Configuration, $t_i$是预测transition。
模型采用交叉熵损失函数,并使用l2正则化:
$$L(\theta) = - \sum_i \log p_{t_i} + \frac{\lambda}{2}||\theta||^2$$
$\theta$是所有的参数${W_1^w,W_1^t,W_1^l,b1,W_2,E_w,E_t,E_l}$,最后使用softmax来做预测。
对于参数的初始化,我们使用预训练词嵌入l来初始化$E^w$,使用(-0.01,0.01)来初始化$E^t$, $E^l$。英语的预训练词嵌入来自于(Collobert et al., 2011)(#dictionary = 130,000, coverage = 72.7%),和我们的基于维基的50维度word2vec词嵌入 (Mikolov et al., 2013) ,以及中文语料库的Gigaword (#dictionary =285,791, coverage = 79.0%)。我们也做了随机初始化$E^w$对比试验,详见Section4。模型使用反向传播算法来训练嵌入。
模型使用 mini-batch AdaGrad作为优化器,并使用Dropout(0.5)技术。在开发集上上无标签成就分数(unlabeled attachment score)最高的参数模型作为最终选择。
3.3 Parsing
在解析过程中我们选择贪婪解码。在每一步,我们从当前配置Configuration $c$中抽取所有对应的单词,POS和标签嵌入,然后计算$h(c) \in \mathbb{R}^{d_h}$,选择最高分 $t=\text{arg max}_{t \text{ is feasible}}W_2(t,\cdot)h(c)$,然后执行 $c \rightarrow t(c)$。
与indicator features相比,我们的解析不需要计算连接特征和在巨大特征表中检索,因此特征生成时间大幅减少。其包含大量矩阵加法和乘法操作。为了进一步提高速度,我们采用pre-computation技巧。对 $S^w$,我们预先计算每个位置的最常见10000个单词。因此,隐层计算只需要检索,然后添加 $d_h$维向量。同样,可以计算POS和边标签每个位置的10000个单词。我们只在神经网络解析器中使用这个优化方法,能加速8-10倍。
4 Experiments
4.1 Details
数据集:English Penn Treebank(PTB) 和 Chinese Penn Treebank(CTB)。图三是三个数据集的统计情况。
##4.2 Results
超参数设置:嵌入维度$d$=50,隐层大小$h$=200,正则化率 $\lambda = 10^{-8}$,AdaGrad学习率 $\alpha = 0.01$。
同时,我们自己实现了arc-eager算法和arc-standard算法作为对比实验。此外,还与最新的两个解析器进行比较,MaltPaser - 基于转移的贪婪式依赖解析(a greedy transition-based dependency parser)(Nivre et al., 2006), MSTParser - 基于图的先序解析器(a first-order graph-based parser)(McDonald 2006)。
评估参数:LAS(labeled attachment score) 和 UAS(unlabeled attachment score)。测试环境i7 2.7Ghz 16G RAM
在三个数据集的结果: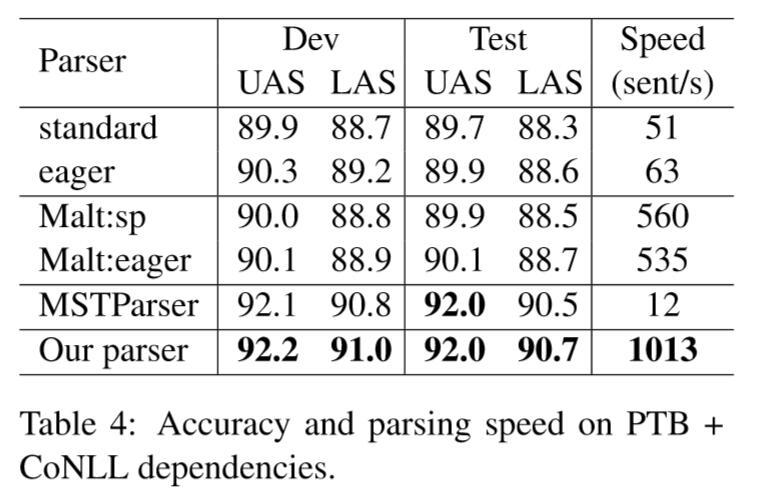
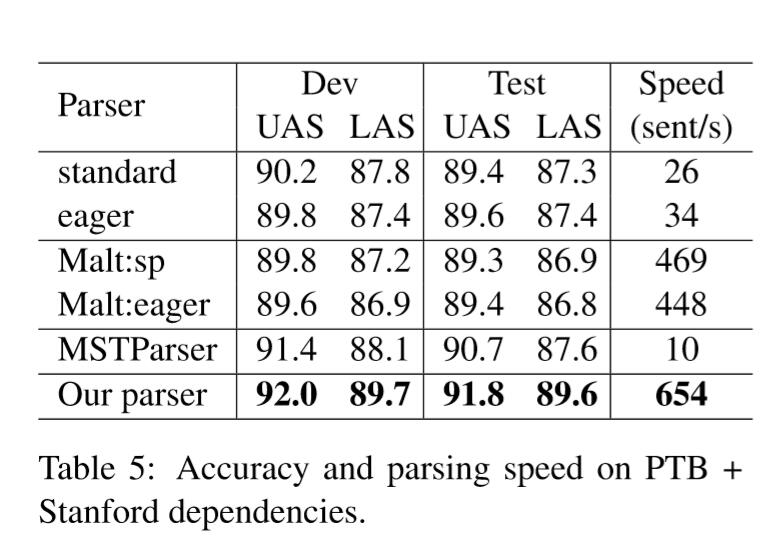
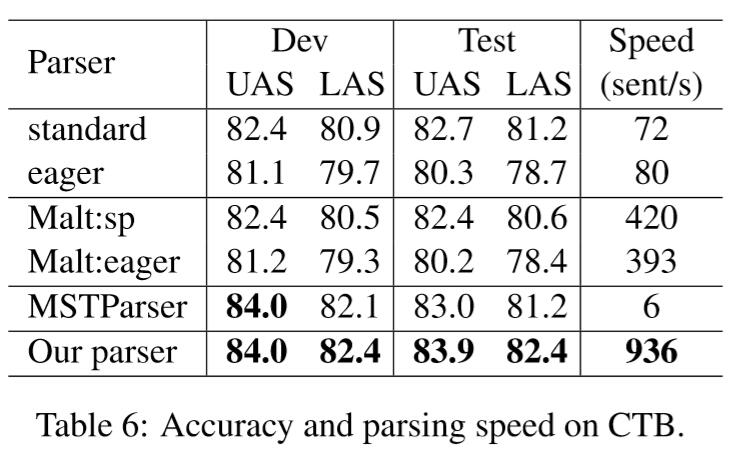
准确率基本第一梯度,速度基本碾压。
4.3 Effects of Parser Components
Cube activation function
简而言之,Cube比其它激活函数激活高0.8~1.2%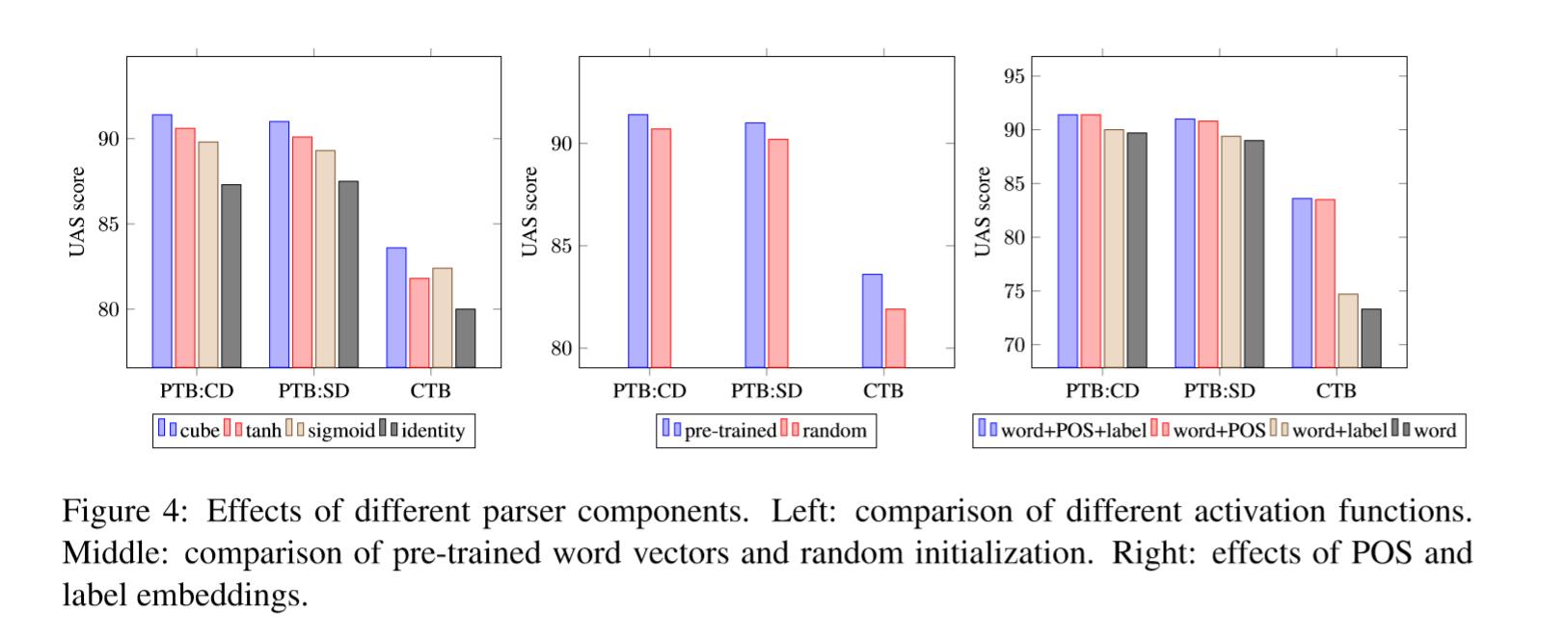
Initialization of pre-trained word embeddings
预训练在PTB上有0.7%的提升,CBT上1.7%的提升
POS tag and arc label embeddings
使用三者结合准确率最高。
4.4 Model Analysis
最后,我们研究了参数学习到了什么,特征捕获了什么。
What do $E^t$, $E^l$ capture?
使用t-SNE算法对特征进行可视化,如图5。这些嵌入有效地展示了POS标签或弧标签之间的相似性。POS中JJ,JJR,JJS非常相近。acomp,ccomp,xcomp分到了一起。我们有理由相信,POS嵌入对NLP其他任务也会有帮助。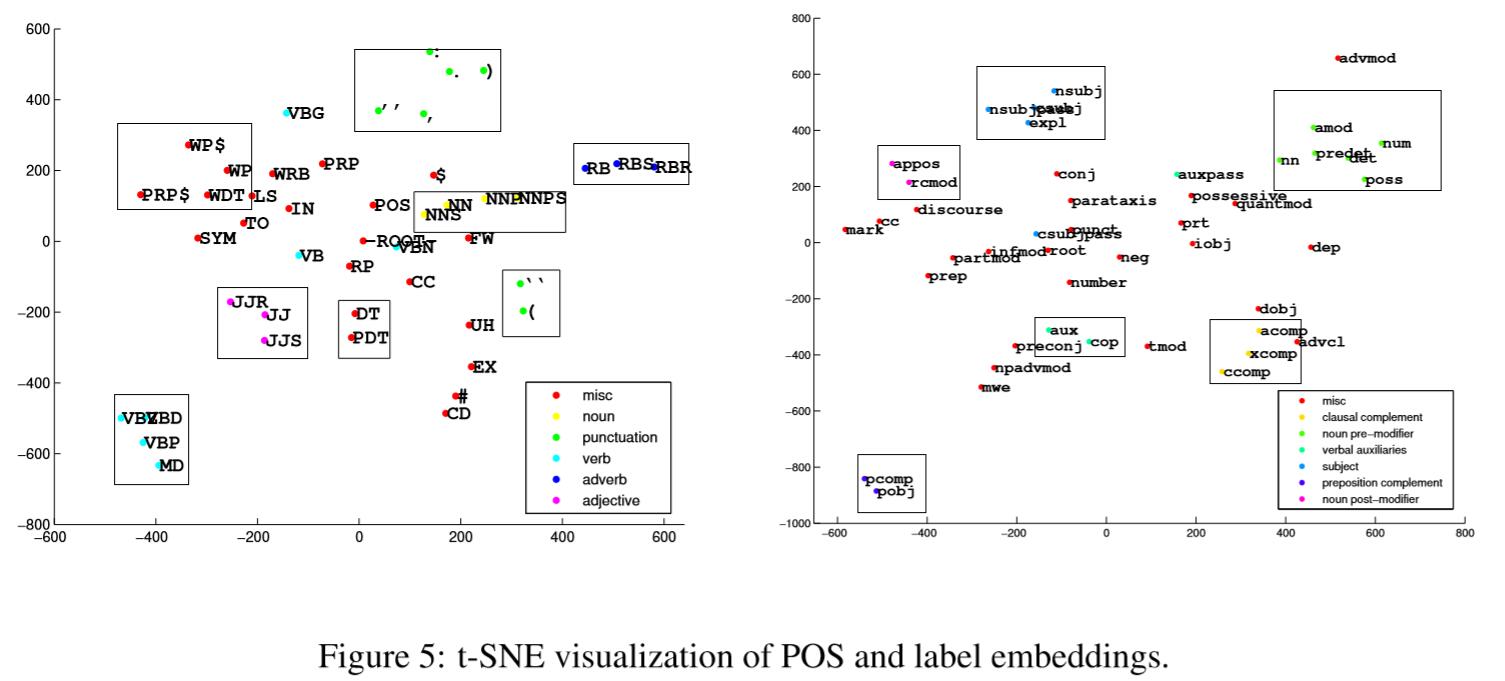
What do $W_1^w,W_1^t,W_1^l$ capture?
在了解$E^t$,$E^l$像$E^w$一样能学习到语义信息后,我们想研究每个特征在隐藏中学习到什么。
我们想知道隐层大小$h=200$是否学习到足够的信息。对每个隐层单元$k$,将其权重reshape成 $d \times n_t, d \times n_w, d \times n_l$。这样每个元素和词嵌入矩阵是保持一致的。
我们选取绝对值大于0.2的权重,然后对每个特征可视化它们。图6是三个采样特征,可以看到很有趣的现象:
- 不同的特征权重分布式多样的。 然而,大多数判别权重来自$W_1^t$(图6中的中间区域),并且这进一步证明了POS标记在依赖性解析中的重要性。
- 我们仔细研究了$h=200$个特征发现,它们编码了不同的信息。在图6中三个采样点,最大的权重是由以下确定的:
- Feature 1:$s_1.t, s_2.t, lc(s_1).t$
- Feature 2:$rc(s1).t, s1.t, b1.t$
- Feature 3:s_1.t, s1.w, lc(s1).t, lc(s1).l
通过在indicator feature 实验上观察,这些特征非常合理。我们的模型自动识别最有用的信息来进行预测,而不用手工创建。
- 我们可以轻松提取三个以上元素特征,包括indicator feature没有的特征。

5 Related Work
6 Conclusion
我们使用神经网络提出了一种新颖的依赖解析器。 实验评估表明,我们的解析器在精度和速度方面都优于使用sparse indicator features 的其他贪心解析器。 这是通过将所有单词,POS标签和圆弧标签表示为密集向量,并通过新颖的立方体激活函数对其交互进行建模来实现的。 我们的模型仅依赖于密集的特征,并且能够自动学习最有用的特征连接以进行预测。
接下来工作是结合神经网络分类器和search-based 模型来进一步提高精度。当然,网络模型还有提升的空间。