03.结构化机器学习项目
第一周
1.1 为什么是ML策略
经验:如何进一步优化模型
1.2 正交化
正交化是指,在模型的调参过程中,尽量选择影响单一化的方法。
第一组按钮用来调节宽度,方法包括 - bigger network - Adam算法
第二组按钮用来调节高度,方法包括 - 正则化 - 增加数据集
第三组 - 增加数据集
第二组 - 改变损失函数 - 改变开发数据集
一般不使用early stopping,它会同时影响前两步,违反正交化,使模型不好分析。
1.3 单一数字评估指标
使用单一数字(实数)指标进行模型的评估。如F1值:$\frac{2}{\frac{1}{P}+\frac{1}{R}}$
重申:idea<->code<->experiment
1.4 满足和优化指标
当有多个指标去衡量目标的话,可以选择一个作为优化指标(optimizing metric),其它的设置为满足指标(satisficing metric)
- 如猫学习器准确率作为optimizing metric,识别速度小于100ms作为satisficing metric
- 如语音唤醒设备,准确率作为optimizing metric,24小时内只能一次假阳性唤醒作为satisficing metric
1.5 训练/开发/测试集的划分
开发集/保留交叉验证集 和 测试集 应保持数据同分布
新收集的数据也应同时分布在开发集和测试集上
1.6 开发集和测试集的大小
传统的8:2或6:2:2方式不再适合大数据下的当代
深度学习对训练数据量的要求非常大,因此,当数据大于百万时候,使用98:1:1是没有问题的。
一般强调设置 训练集、开发集、测试集
有时候忽略测试集不推荐
1.7 什么时间开始改变开发/测试集和指标
如果无法正确评估好算法的排名,则需要定义一个新的评估指标。
算法a在识别猫图时可能会推送成人图片,则需要修改error指标:
$$Error: \frac{1}{m_{dev}} \sum_{i=1}^{m_{dev}}L({\hat y}^{(i)},y^{(i)}) \tag{1}$$
$$Error: \frac{1}{\sum \omega^{(i)}} \sum_{i=1}^{M_{dev}}\omega^{(i)}L({\hat y}^{(i)},y^{(i)}) \tag{2}$$
$$\omega^{(i)}=
\begin{cases}
1& \text{if} \ x^{i}\ \text{is non-porn}\\
10& \text{if} \ x^{i}\ \text{is porn}
\end{cases}$$
在当前开发集和测试集表现很好,但在实际应用中表现不好时,需要修改指标换切换数据集。
1.8 为什么是人的表现
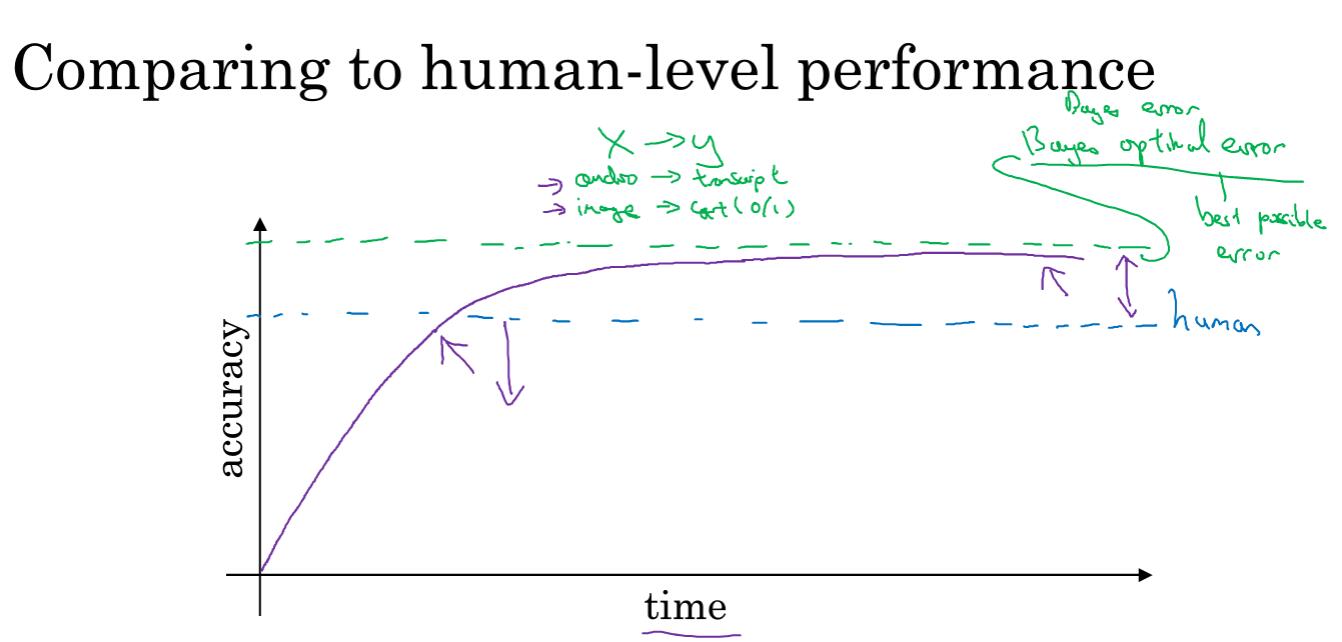
贝叶斯最优误差(Bayes optimal error)是理论上可能达到的最优误差,
如果你的模型比人类水平低,说明可以使用某些工具来提高性能。
模型效果低于人类水平,你可以
- 人为标注更多类别数据
- 人工误差分析:为什么人类做的对?
- 更好的偏差/方差分析
1.9 可避免偏差

将人类水平看作是贝叶斯误差,贝叶斯误差和训练集的错误率记为可避免偏差(Avoidable bias),
- 当可避免偏差过大,要先降低训练集的错误率。如情况A
- 当可避免偏差很小,解决方差。如情况B
1.10 理解人的表现
Human-level error定义:替代贝叶斯误差。
- 一般人对放射科的识别误差为3%
- 一般医生的误差为1%
- 专家医生的误差为0.7%
- 专家团队的误差为0.5%
可以得知 bayes error <= 0.5%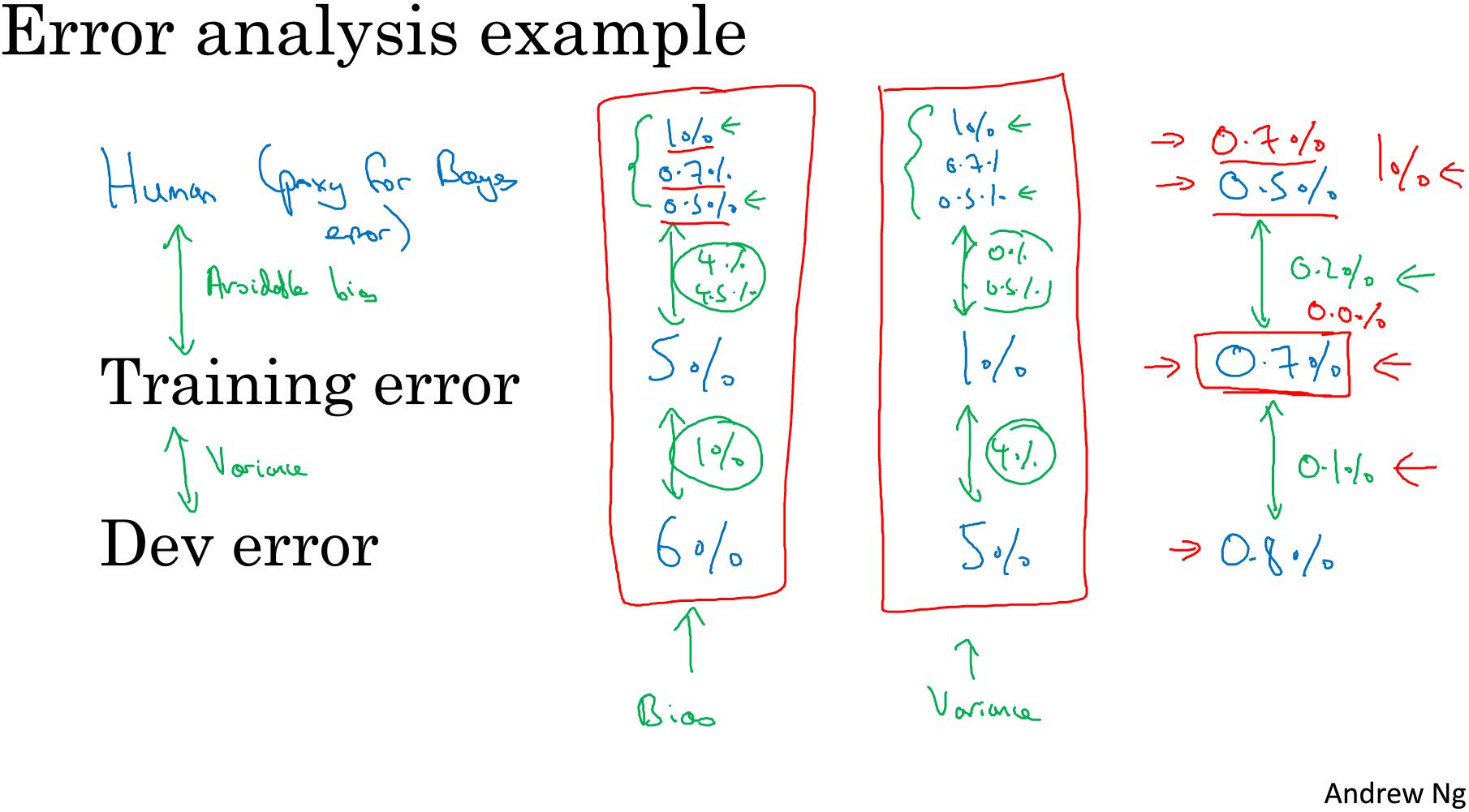
比较Avoidable bias 和 Variance大小可以分析应解决偏差还是方差问题。
1.11 超过人的表现
| Scenario | Human-level | training set error | development error |
|---|---|---|---|
| A | 0.5% | 0.6% | 0.8% |
| B | 0.5% | 0.3% | 0.4% |
在情况A下Avoidable Bias为0.1,Variance为0.2,故应该着重降低方差。
但在情况B下,模型超过人类,很难用现有的工具和方法去判断应降低偏差还是方差。
在结构化数据中,机器学习算法很容易超越人的表现。
但在自然感知领域,人类比较擅长,但机器学习能够一定程度上超过人类。
1.12 改善你模型的表现
- 减小可避免偏差
- 更大的模型
- 训练更久,优化算法(momentum, RMS prop, Adam, activation function)
- 更换网络结构(RNN,CNN),超参数搜索
- 减小方差
- 更多数据
- 正则化(L2, Dropout, data augmentation)
- 更换网络结构(RNN,CNN),超参数搜索
第一周作业
选择题 可参考网上相关资料
第二周
2.1 进行误差分析
误差分析:通过人工检查分析错误样本点,来进行下一步的优化。
一个猫分类器错误地将狗识别成了猫,目前误差是$10\%$
是否应该专门去处理狗?
误差分析:
- 随机抽取开发集中100个错误样本
- 统计狗的数量
结果:
- $5\%$是狗,则花费很多时间处理狗,误差会从$10\%$降低到$9.5\%$,即性能提升的Ceiling为$9.5\%$。
- $50\%$是狗,那么误差会从$10\%$降低到$5\%$,值得尝试。
多个想法的并行评估
猫分类器的优化idea:
- 修复狗识别成猫问题
- 修复狮子等大猫被错误分类
- 更好地图片模糊处理
| Image | Dog | Great Cats | Blurry | 分析中新的类别 | Comments |
|---|---|---|---|---|---|
| 1 | ✔ | 比特犬 | |||
| 2 | ✔ | ||||
| 3 | ✔ | ✔ | 动物园下雨 | ||
| … | … | … | … | ||
| %of total | 8% | 43% | 61% | 12% | - |
然后通过人为分析,比如解决Great Cats问题,或同时解决图像模糊问题。
这个统计步骤大概需要几小时,但是值得。
2.2 清除标注错误的数据
深度学习对随机误差(少量的数据标记出错)鲁棒性(robust),但对系统误差没有。
在误差分析的时候添加一列:数据标记类别出错,进行分析。
是否进行样本类别修正?
- 如果这些标记错误严重影响了模型在开发集的评估能力,需要修复。
- 没有,则不需要花费宝贵时间修正。
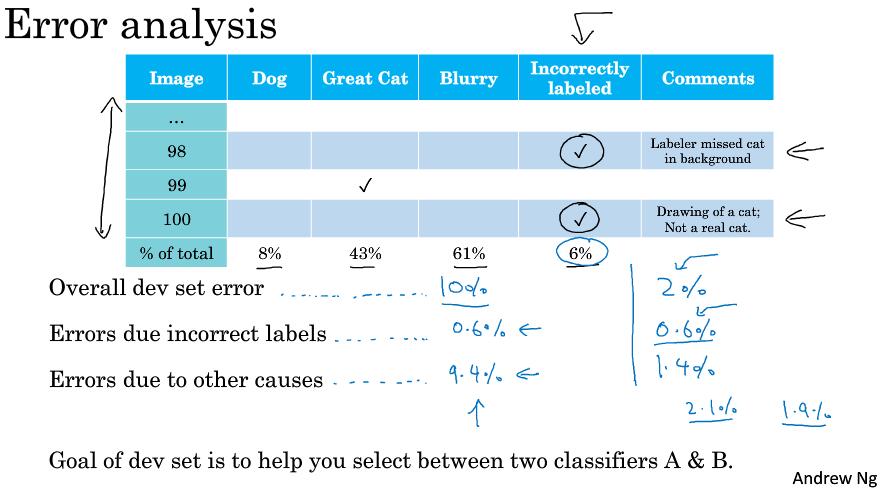
第一种情况下,其它错误占9.4%远大于标记错误问题,所以应多处理其它错误。第二种情况下,标记错误类别比较大,需要处理。
修正开发集/测试集错误样本
- 在开发集,测试集上使用相同的处理,保证数据同分布
- 同时检查算法中正确和错位的样例
- 训练集和开发测试集处于轻微的不同分布。之前提到训练集对随机误差有鲁棒性,且训练集比开发测试集大很多,不做标记修正也是可以的,之后细谈这个问题。
深度学习不仅是使用模型,还更多在模型优化,调参,分析误差上。
2.3 快速搭建你的第一个系统,并进行迭代
快速建立原型系统,然后进行迭代。
- 快速设立开发测试集和评估指标
- 建立机器学习系统原型
- 使用偏差/方差分析和误差分析决定下一步
如果研究的问题有大量的文献参考资料,可以先了解然后一开始就建立比较复杂的模型
2.4 在不同的划分上进行训练和测试
训练集和开发测试集要保持同分布不一定完全对
一、 想要训练识别APP用户上传的猫图分类器,有200K网页抓取猫图(清晰)数据,和10KApp用户上传数据(真实应用,模糊不专业)。这种情况下去做数据的划分有两种选择:
- 将两个数据集合并打乱,划分如下。虽然保证了数据的同分布,但在开发集2.5K数据中,仅有119张是App数据,靶心更多地指向了网页抓取猫图,因此,这种方式是不可行地。
| 训练集 | 开发集 | 测试集 |
| 205k | 2.5k | 2.5k |- 将App的10K数据分为2.5k,2,5k,5k。两个2.5k分别作为开发集和测试集,5k和网页抓取200K数据一起作为训练集,虽然训练集和开发测试集数据分布不同,但靶心是正确的。
二、想要建立一个汽车后视镜语音识别模型,有买的语音识别数据500k,和与后视镜交互的真实应用数据20k
数据集的划分应该为,将真实数据中的5K分别做开发集和测试集,剩余的进行训练集
2.5 不匹配数据划分的偏差和方差
偏差和方差分析可以帮助你进行下一步的优化,训练集和开发测试集的数据分布不同时候,偏差和方差分析方法需要调整。需要设立训练-开发集(train-dev set)进行分析。
训练-开发集(train-dev set):和训练集同分布,但没有用于训练。
误差分析情况示例:
| - | Scenario A | Scenario B | Scenario C | Scenario D |
|---|---|---|---|---|
| Human-error | - | - | 0% | - |
| Train error | 1% | 1% | 10% | 10% |
| Train-dev error | 9% | 1.5% | 11% | 11% |
| Dev error | 10% | 10% | 12% | 20% |
| Problem | Variance | data mismatch | Bias | Bias & data mismatch |
avoidable error:Human-error - Train error
variance:train error - train-dev error
data mismatch: train-dev error - dev error
degree of overfit:dev error - test error
考虑下面的情况:
| 编号 | - | - | 与上一行差值 |
|---|---|---|---|
| 1 | Human-error | 4% | - |
| 2 | Train error | 7% | avoidable error |
| 3 | Train-dev error | 10% | variance |
| 4 | Dev error | 6% | data mismatch |
| 5 | Test error | 6% | degree of overfit |
2,3是根据训练集分布评估的,4,5是根据开发集分布评估的,需要一个更通用的分析,以汽车后视镜语音为例:
| - | General speech recognition | Reaview mirror speech data |
|---|---|---|
| Human level | human level 4% |
6% |
| Error on examples on trained | Traing error 7% |
6% |
| Error on examples on not trained | Training-dev error 10% |
Dev/Test error 6% |
首先分析红色四个数据,能给出优化方向
把表格中右上两个数字得到,左右对比分析很有用
最后一行说明实际任务对比训练任务更简单,但一行差值又表明不是那么简单
data mismatch没有很系统的解决方法,但有一些尝试建议
原图如下: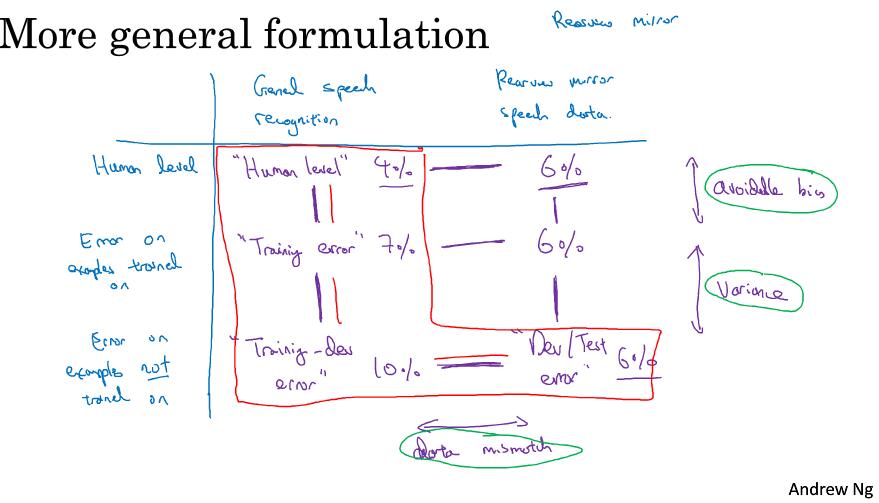
2.6 定位数据不匹配
数据不匹配问题进行误差分析,1)尝试了解两个数据分布的不同之处,2)收集等多的像开发集一样的数据,如通过人工合成数据。
使用人工合成数据要警惕:从所有可能性的空间只选取了很好一部分去模拟数据,从而导致算法对这一部门过拟合。
以汽车后视镜语音系统为例子
可以在清晰的数据集上人为与汽车噪声数据合成,但注意,汽车噪声不应该仅仅是一个小时,而应该是很大的,近似于清晰数据集。不然很容易对这一小时的汽车噪声过拟合。
2.7 迁移学习
迁移学习的应用场景:
- 当你想从任务A并迁移一些知识到任务B,当任务A和任务B都有同样的输入X时,迁移学习时有意义的。
- 当你拥有任务A的数据大于任务B时候
- 任务A的低层特征对任务B是有效的
迁移学习将神经网络最后一层或多层进行重新初始化和训练,迁移学习又叫预训练。
2.8 多任务学习
多任务学习使用频率低于迁移学习
多任务学习比单任务学习效果要好,如果不好说明网络不够深
多任务学习在计算机视觉,目标检测有很广应用。
多任务学习最后一层不再使用softamx,单一样本的类别不再是onehot向量表示,$y$成为各个类别的0,1表示。损失函数:$Loss=\underset{(4,1)}{\hat{y}^{(i)}}$变为:$\frac{1}{m}\sum_i^m\sum_j^4L(\hat{y}_j^{(i)}, y_j^{(i)})$
2.9 什么是端对端的深度学习
以前的数据处理系统或学习系统,需要多个阶段的处理,end to end learning则是忽略所有这些不同的阶段,用单个神经网络来代替它。
但端对端学习并不使用所有场景:
- 百度的人脸门禁系统,将其拆分成1.判断是否有人脸并进行图片切割2.判断人物身份
- 机器翻译,使用端对端学习相比传统的一步步收取特征再转换有效,且有大量的数据集
- 根据手骨判断儿童年龄,数据量太小。无法支撑端对端学习,而传统的切割手骨判断长度再判断年龄比较合适
2.10 是否使用端对端学习
优势:
- 让数据说话(黑盒)。不要强迫机器学习C A T,以音位为单位去学习进行语音识别。(联想到用语法做文本分析,结果一沓糊涂)
- 降低手工设计的组件需要
劣势:
- 需要非常大量的数据
- 排除了可能有用的手工设计组件,精心设计的组件可能很有用,也可能限制学习器的学习思维。
使用端对端(end to end learning)的建议:
关键:是否拥有足够的数据来学习从x到y足够复杂(complexity needed)的函数。
无人驾驶技术,并不是简单的端对端学习:
而是把DL用来学习构成部分组件。
深度学习做预测,决策是更上层的目标。-沈华伟